目录
一.设计任务&&要求:
二.方案设计报告:
2.1 哈夫曼树编码&译码的设计原理:
2.3设计目的:
2.3设计的主要过程:
2.4程序方法清单:
三.整体实现源码:
四.运行结果展示:
五.总结与反思:
一.设计任务&&要求:
题目要求:测试数据是一段任意的英文,也可以是一段完整的中文,采用哈夫曼算法进行编码,可输出对应的字符编码的解码
哈夫曼编码是一种最优变长码,即带权路径最小。这种编码有很强的应用背景,是数据压缩中的一个重要理论依据。对输入的一串文字符号实现哈夫曼编码,再对哈夫曼编码生成的代码串进行译码,输出字符串。要求完成以下功能:
1.针对给定的字符串,建立哈夫曼树。
2.生成哈夫曼编码。
3.对编码字符串译码。
2.1 哈夫曼树编码&译码的设计原理:
哈夫曼
编译码器的主要
功能是先建立哈夫曼树,然后利用建好的哈夫曼树生成哈夫曼编码后进行译码。在
数据通信中,通常需要将传送
文字转换成由二进制字符0,1组成的二进制串,称之为编码。构建一个哈夫曼树,设定哈夫曼树中的左
分支为0,右
分支代表1,则从根结点到每个叶子节点所经过的
路径组成的0和1的序列便为该节点对应字符的编码,称之为哈夫曼编码。最简单的二进制编码方式是等长编码。若采用不等长编码,让出现频率高的字符具有较短的编码,让出现频率低的字符具有较长的编码,这样可以有效缩短传送
文字的总长度。哈夫曼树则是用于构造使编码总长最短,最节省空间成本的编码方案。
2.3设计目的:
(1) 巩固和加深对数据结构课程所学知识的理解,了解并掌握数据结构与算法的设计方法;
(2) 初步掌握软件开发过程的问题分析、系统设计、程序编码、测试等基本方法和技能;
(3) 提高综合运用所学的理论知识和方法,独立分析和解决问题的能力;
(4) 训练用系统的观点和软件开发一般规范进行软件开发,培养软件工作者所应具备的科学的工作方法和作风;
(5) 培养查阅
资料,独立思考
问题的能力。
2.3设计的主要过程:
1.哈夫曼树叶子节点的创建
叶子节点需要存储字符,及其出现的频率,指向左右子树的指针和将来字符所编码成的二进制数字。这里用一个静态内部来来初始化树的叶子节点:
public Node(int freq, Node left, Node right) {
public void setCh(char ch) {
public void setFreq(int freq) {
//重写的toString 方法只需要打印字符和其对应的频次即可
public String toString() {
2.构建哈夫曼树
构建过程:首先要统计每个字符出现的频率①.将统计了出现频率的字符,放入优先级队列中,利用优先级队列的特点,将字符按照出现的频率从小到大排序②.每次出队两个频次最低的元素,给它们找一个父亲节点③.将父亲节点放入队列中,重复②~③两个步骤④.当队列中只剩一个元素时,哈夫曼树就构建完了
//->由于这里是一个自定义的类,我们需要传入比较器,按照节点的频次进行比较
PriorityQueue<Node> q = new PriorityQueue<>(
//通过Comparator 的方法来获得Node节点的其中一个属性
Comparator.comparingInt(Node::getFreq)
for(Node node : hash.values()){
int freq = x.freq + y.freq;
q.offer(new Node(freq,x,y));
3.哈夫曼编码
通过将每个叶子节点保存好的字符编码利用StringBuilder中的append()方法拼接起来后返回即可
char[] chars = str.toCharArray();
StringBuilder sb = new StringBuilder();
sb.append(hash.get(c).code);
4.哈夫曼译码
从根节点开始,寻找数字对应的字符编码,如果是0向右走,如果是数字1向左走,如果没有走到头(一个字符的编码结尾),每一步数字的索引cur++,每找到一个编码字符,在将node重置为根节点,接着重个节点开始继续往下寻找,一直找到字符串末尾即可
* 走到头就可以 找到编码字符,再将node 重置为根节点
public String decode(String str){
char[] chars = str.toCharArray();
StringBuilder sb = new StringBuilder();
while(cur < chars.length){
if(!node.isLeaf()){//非叶子节点
if(chars[cur] == 0){//向左走
}else if(chars[cur] == 1){//向右走
//每找到一个叶子节点,就重置后再次查找,直到遍历完整个数组
大致模块图:
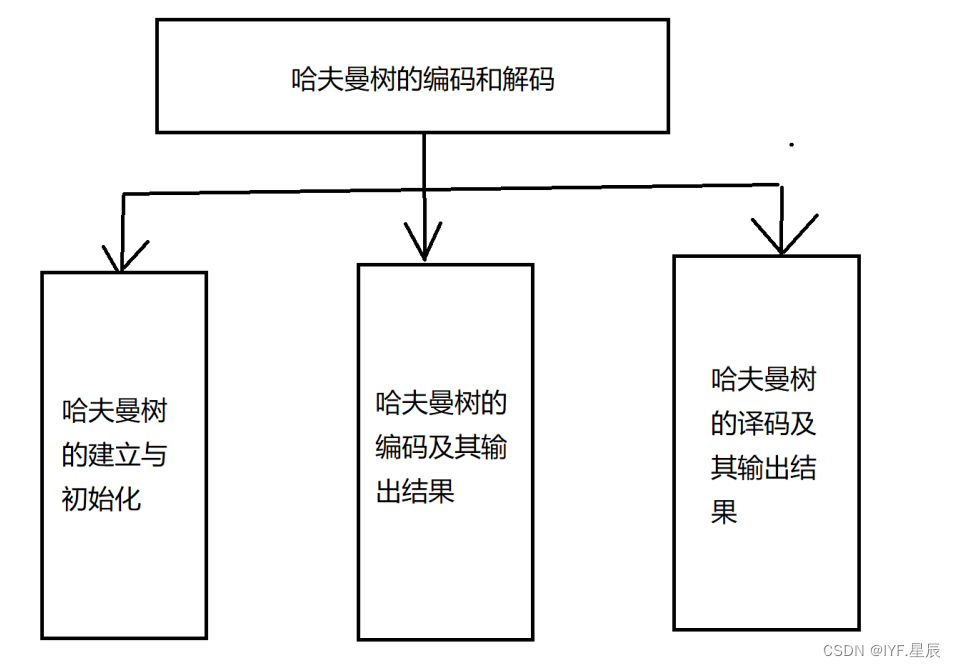
设计流程图:
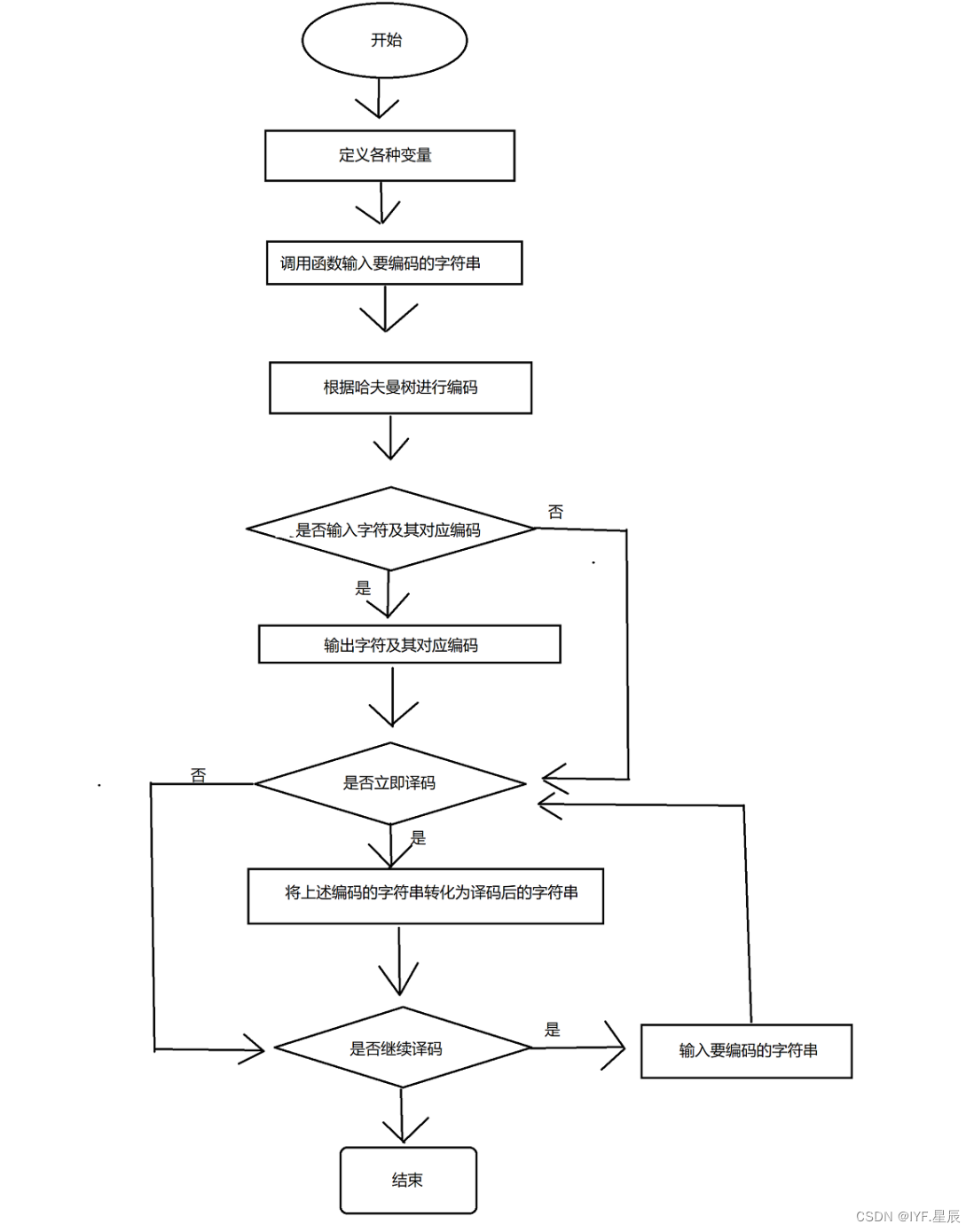
2.4程序方法清单:
①.构造哈夫曼树:public HuffmanTree(){
}//这里我选择在函数的构造方法中将哈夫曼树给先构造完
②.编码:public String encode(){};
③.解码:pulbic String decode(){};
④.找到编码,并计算其对应的bit位:private int findCode(Node node,StringBuilder code){};
⑤.打印菜单:menu(){};
⑥.测试函数:main(){};
模块展示:
三.整体实现源码:
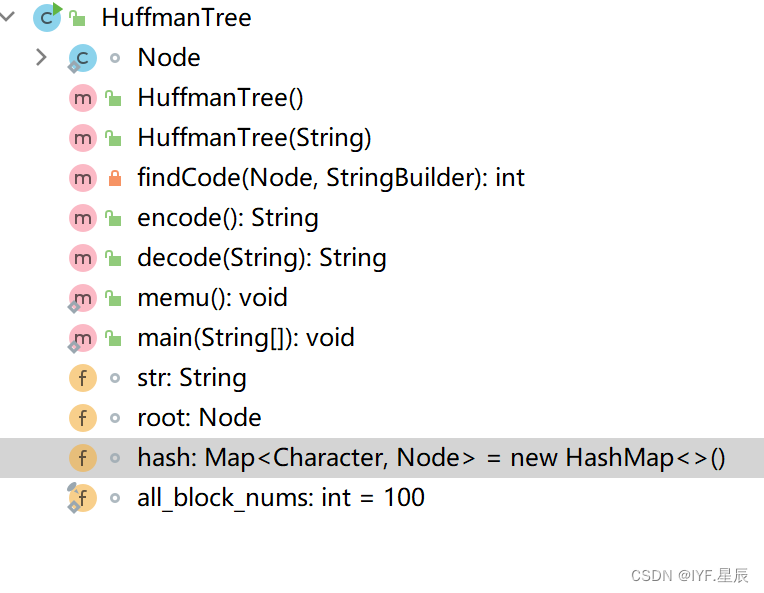
public class HuffmanTree {
public Node(int freq, Node left, Node right) {
public void setCh(char ch) {
public void setFreq(int freq) {
//重写的toString 方法只需要打印字符和其对应的频次即可
public String toString() {
Map<Character,Node> hash = new HashMap<>();
public HuffmanTree(String str){
char[] chars = str.toCharArray();
if(!hash.containsKey(ch)){
hash.put(ch,new Node(ch));
Node node = hash.get(ch);
for(Node node : hash.values()){
System.out.println(node);
//->由于这里是一个自定义的类,我们需要传入比较器,按照节点的频次进行比较
PriorityQueue<Node> q = new PriorityQueue<>(
//通过Comparator 的方法来获得Node节点的其中一个属性
Comparator.comparingInt(Node::getFreq)
for(Node node : hash.values()){
int freq = x.freq + y.freq;
q.offer(new Node(freq,x,y));
//System.out.println(root);
System.out.println("输出编码信息:");
int sum = findCode(root,new StringBuilder());
for(Node node : hash.values()){
System.out.println(node + " " + node.code);
System.out.println("总共占有的bit位是:" + sum);
private int findCode(Node node,StringBuilder code){
node.code = code.toString();
sum = node.freq * code.length();
sum += findCode(node.left,code.append("0"));
code.deleteCharAt(code.length() - 1);
sum += findCode(node.right,code.append("1"));
code.deleteCharAt(code.length() - 1);
char[] chars = str.toCharArray();
StringBuilder sb = new StringBuilder();
sb.append(hash.get(c).code);
* 走到头就可以 找到编码字符,再将node 重置为根节点
public String decode(String str){
char[] chars = str.toCharArray();
StringBuilder sb = new StringBuilder();
while(cur < chars.length){
if(!node.isLeaf()){//非叶子节点
if(chars[cur] == 0){//向左走
}else if(chars[cur] == 1){//向右走
//每找到一个叶子节点,就重置后再次查找,直到遍历完整个数组
static final int all_block_nums = 100;
public static void memu() throws InterruptedException {
for(int i = 0;i < all_block_nums;i++){
System.out.printf("\r[%d%%]>",i*100/(all_block_nums-1));
for(int j = 1;j <= i*20/(all_block_nums);j++){
System.out.println("-------------------------------------------");
System.out.println("---------- ------------");
System.out.println("-------- 欢迎使用哈夫曼编码 ----------");
System.out.println("--------- 1.编码与解码 ---------");
System.out.println("---------- 0.退出 ----------");
System.out.println("-------------------------------------------");
public static void main(String[] args) throws InterruptedException {
Scanner sc = new Scanner(System.in);
System.out.println("请选择:");
int input = sc.nextInt();
System.out.println(
"你选择了退出程序~~~");
System.out.println("你选择了编码与解码");
System.out.println("请输入要编码的字符串:");
HuffmanTree huffmanTree = new HuffmanTree(in);
str = huffmanTree.encode();
System.out.println("编码后的字符串为:");
System.out.println("将刚才编码好的字符串进行解码:");
String cur = huffmanTree.decode(str);
System.out.println("解码后的字符串:");
四.运行结果展示:

五.总结与反思:
这次课程设计的心得体会通过实践我的收获如下:
① 巩固和加深了对数据结构的理解,提高综合运用本课程所学知识的能力。
② 培养了我选用参考书,查阅手册及文献资料的能力。培养独立思考,深入研究,分析问题、解决问题的能力。
③ 通过实际编译系统的分析设计、编程调试,掌握应用软件的分析方法和工程设计方法。
④ 通过课程
设计,培养了我严肃认真的工作作风,逐步建立正确的生产观念、经济观念和全局观念。
通过本次数据结构的课设计,我学习了很多在上课没懂的知识,并对求哈夫曼树及哈夫曼编码/译码的算法有了更加深刻的了解,更巩固了课堂中学习有关于哈夫曼编码的知识,真正学会一种算法了。当求解一个算法时,不是拿到问题就不加思索地做,而是首先要先对它有个大概的了解,接着再详细地分析每一步怎么做,无论自己以前是否有处理过相似的问题,只要按照以上的步骤,必会顺利地做出来。
结语: 写博客不仅仅是为了分享学习经历,同时这也有利于我巩固知识点,总结该知识点,由于作者水平有限,对文章有任何问题的还请指出,接受大家的批评,让我改进。同时也希望读者们不吝啬你们的点赞+收藏+关注,你们的鼓励是我创作的最大动力!