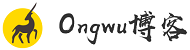
【银河麒麟服务器操作系统】系统夯死分析及处理建议
了解银河麒麟操作系统更多全新产品,请点击访问麒麟软件产品专区:https://product.kylinos.cn
服务器环境以及配置
【机型】物理机
【内核版本】
4.19.90-25.26.v2101.ky10.x86_64
【OS镜像版本】
银河麒麟Kylin-Server-10-SP2-Release-Build09-20210524-x86_64
【第三方软件】
TDSQL
现象描述
服务器在13:40左右发生夯死现象。初步排查系统日志,发现系统日志记录了oom问题,但是当时并没有重启系统,系统cpu急剧增加,最终系统夯死。数据库已提供数据库层面分析报告,需要系统层面再进行问题分析排查。
问题分析
分析系统日志,已知,系统重启时间为2024-03-11 15:18:23,故障时间在2024-03-09 13:46:32左右,如图1和图2:

图1

图2
分析系统性能日志,可以看到,2024-03-09 13:10到13:41分钟左右这个时间段内,CPU %system使用率异常高,表示 CPU 在内核运行的时间多,包括 IRQ 和 softirq。系统CPU占用越高,表明系统某部分存在瓶颈。如图3:

图3
分析系统CPU性能情况和负载,可知,故障时间内,系统负载比较高。在每秒创建的进程数(proc)不多的情况下,每秒cswch自愿上下文切换的次数也很高,说明I/O、内存等系统资源不足。如图4和图5:
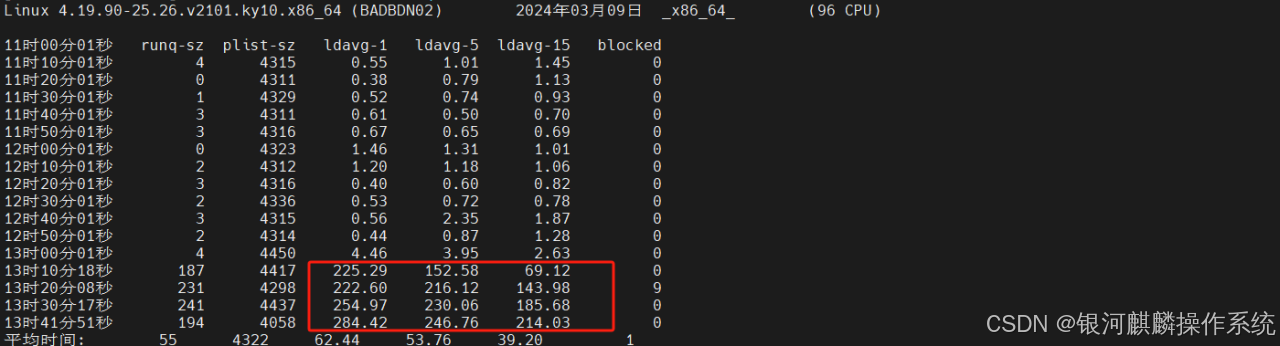
图4
图5
分析内存使用情况,可知,故障时间段内,系统物理内存使用率正常,未到50%。但是,查看内存交换swap,可以看到每秒从交换分区到系统的交换页面和每秒从系统交换到swap的交换页面数量异常增多,已经频繁使用到swap内存交换分区。如图6和图7:

图6
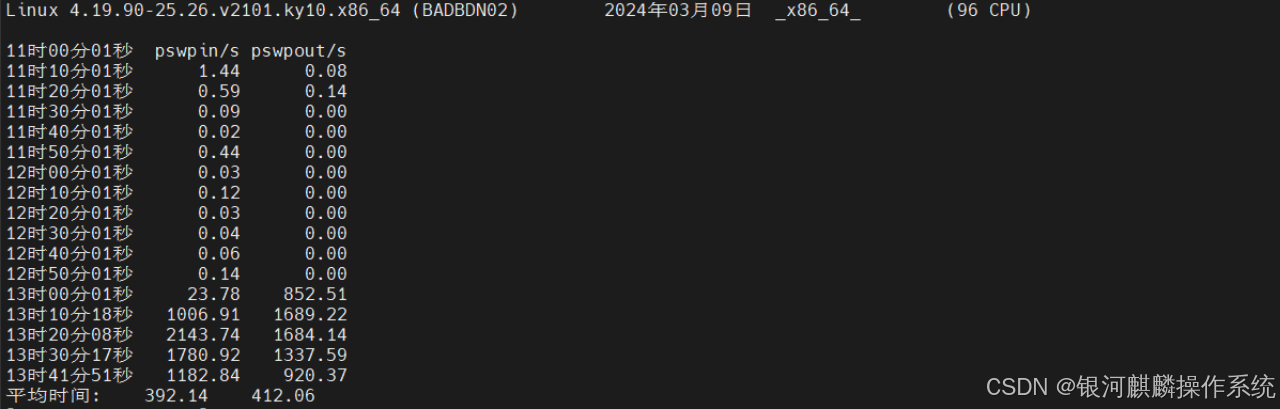
图7
分析系统磁盘IO使用情况,可知,故障时间段内,tps(每秒IO总数)和磁盘IO读写都有明显较大增量。查看磁盘具体IO读写情况,发现,磁盘设备dev8-0(sda)和dev253-1(swap)的%util占比高,说明I/O请求占用CPU多。如图8和图9:

图8


图9
查看vm.swappiness内核参数,已设置为0,表示最大限度使用物理内存,然后才是swap空间,配置,如图10:

图10
分析结果
综上,系统层分析过程,得出,此次系统夯住的原因,是swap内存交换分区异常使用,导致%system系统CPU使用率99%,无法正常分配使用CPU资源。
后续计划与建议
建议,下次遇到此故障情况,观察swap内存交换分区使用情况,排查异常占用swap的具体进程,再进一步分析。
swap进程占用,排查方法如下:
获取到的占用swap空间的进程,在当前目录下生成swap.log文件里查询# for i in `cd /proc;ls |grep "^[0-9]"|awk $0 >100` ;do awk /Swap:/{a=a+$2}END{print "$i",a/1024"M"} /proc/$i/smaps ;done |sort -k2nr > ./swap.log
第一列PID 第二列 swap空间占用大小 由高到低排序# cat ./swap.log
查询下是哪个服务占用的# ps aux | grep pid(swap占用高的)
Ongwu博客 版权声明:以上内容未经允许不得转载!授权事宜或对内容有异议或投诉,请联系站长,将尽快回复您,谢谢合作!